前言
本人萌新,请多指教
2. 1x1卷积层的作用
我们都知道,CNN强于MLP的地方在于其局部连接性减少了过拟合的可能,从而在有限的数据量下可以获取更好的模型。
而CNN是一个基于上下文的网络。对于上下文相关的数据(图像、自然语言等),有着非常理所应当、有理有据的好效果。但是如果filter的大小是1x1呢(本文只探讨2d的CNN,如果要强行说Conv1D我也没办法)?
1x1的filter貌似是上下文无关的。所以1x1的filter与3x3的filter和5x5的filter有着完全不一样的功能。
本萌新读的论文不多,但我记得1x1filter在VGG论文VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION中出现过。VGG指出有1x1的卷积层(VGG的C号架构)物体识别效果比没有(VGG的B号架构)效果好,但是没有3x3的卷积层(VGG的D号架构)效果好。但是并没有给出解释。(顺便一提我认为VGG是ImageNet几篇中最水的一篇,全篇就是在说他用了谁的方法没用谁的方法然后做做做做做实验)
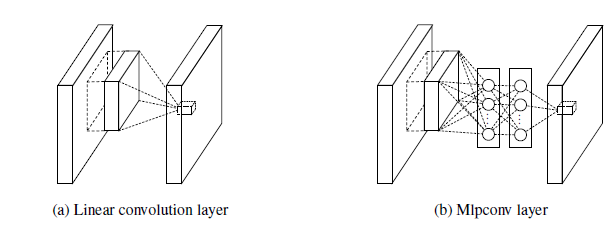
然后1x1的使用比较引起轰动就是在Network in Network中。《Network in Network》整篇论文写的玄乎得要死,什么mlpconv啊什么得,但是实际上观察它得代码就会发现所谓得mlpconv就是1x1得卷积层。仔细想想也是那么回事,实际上1x1的filter由于卷积神经网络的操作已经可以退化为卷积层每个通道的加权求和,然后通过一层激活函数就和单层mlp无异。虽然3x3的卷积核也会有加权求和的操作,但是1x1的卷积核是脱离了上下文的加权求和操作,而3x3是带上下文的加权求和操作
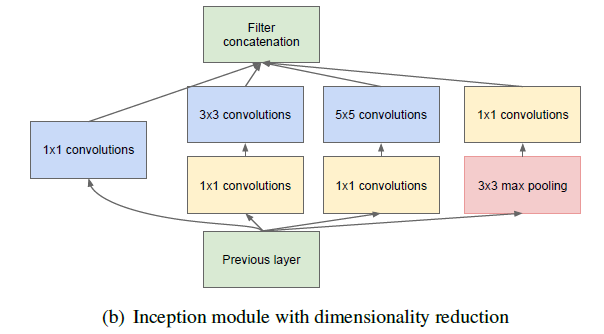
再然后就是Inception中的降维1x1了,我可以将一个28x28x64的卷积层强行压到28x28x20的卷积层,既不增加很多参数数量又能减少卷积层的参数数量,还能加权求和一波,简直非常好用。
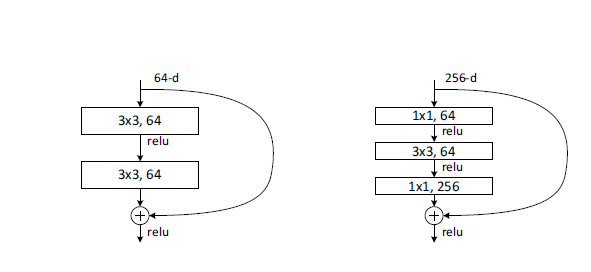
包括resNet中的先降维后升维的操作同理,既可以降低参数数量又可以保持x与F(x)形状不变,可以说是很棒了
所以总结一下,1x1的filter的作用是
- 增加通道之间的交流
- 降维或升维