这篇是ImageNet2017的winner。虽然说ImageNet这个比赛已经凉了,但是SENet还是有一定借鉴的地方的。而且SENet最好的地方在于其高度扩展性。所以SENet配合各种Residual啊Inception啊都是可以的
SENet有点玄。
概述
SENet解决的是图像多分类问题
SENet提出一种神经网络的performance的提升方式是将无需更多的监督(参数)能够获取空间相关性的学习机制显式潜入到网络中。
Inception就是通过这种方式提升performance的。
SENet是通过对特征于特征之间的内部关系进行建模从而提升模型的表现力的。
为此,SENet使用了一些机制完成了特征再标准 (feature recalibration),即通过全局信息去有选择地强调一些重要的特征和压制一些不重要的特征
对于下面卷积神经网络的映射
$F_{tr}:X\rightarrow U 其中 X \in \mathbb{R}^{H’ \times W’\times C’}, U \in \mathbb{R}^{H \times W \times C}$
我们可以建立对应的SE块以如下手段使其完成特征再标准:
- 特征U通过挤压(Squeeze)过程,挤压可以聚集特征的空间维度$H\times W$信息从而产生一个通道描述符。
- 通过激励(Excitation)过程,可以通过每一通道的自门机制学习到样本特定的激活程度
通过这两个操作,特征映射U可以重新获得权重
通过简单的堆叠SE块,我们可以生成一个SE网络
在网络架构中,SE块可以作为一个原来块的简单的替换原件
然而即使块可以插入到任何深度,他在不同的深度下是有不同的意义的。
在浅层,它通过一个类不可知的方式(class agnostic manner)去激励信息特征,加强共享的浅层特征的质量
在深层,SE块变的有专一性,并且对于不同的输入有不同的类特别的回答方式
并且,特征再标准的效益会不断累积下来,作用于整个神经网络
具体内容
SE 块是一个计算单元
卷积核之间的关系由它们的空间信息所捕获
而SE块的目的是去保证网络可以增加对信息特征的敏感并且更好的用于之后的变换,并且压制一些不算很有用的卷积核
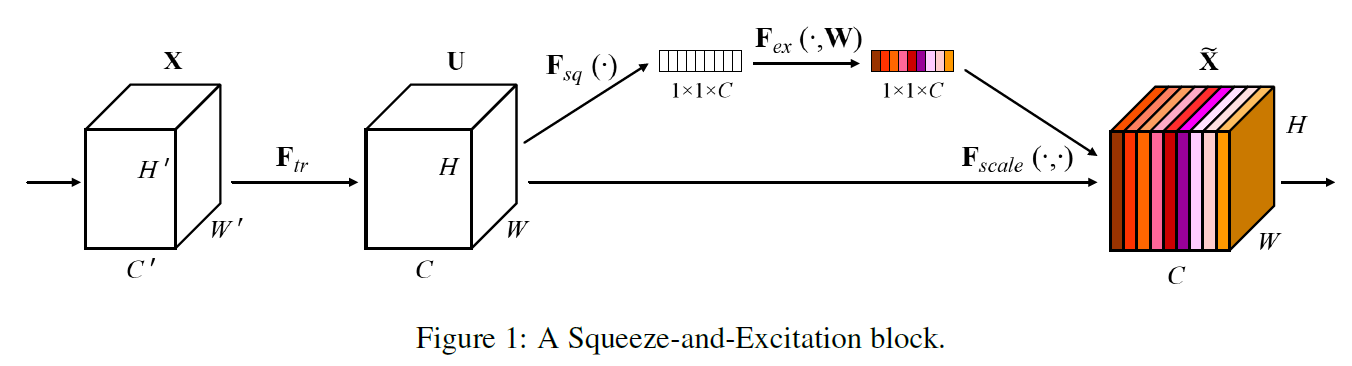
分为两个步骤
挤压(Squeeze)
挤压解决的一个问题是对于卷积核范围之外的感受野的学习。一般限于卷积核大小,CNN对上下文的学习很有限。有的神经网络(Inception,VGG)尝试使用5 5的卷积核去学习,但是一来5 5的卷积核需要更多的参数,二来5 * 5也未必能够解决问题。
为了减轻这个问题,SE块先将每个channel的结果用全局平均池化(Global Average Pooling)挤压成一个1 * 1的通道描述符。
Global Average Pooling的大致操作如下:
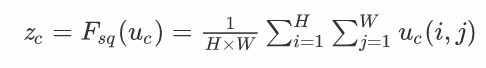
原来的$\mathbb{R}^{H \times W \times C}$被压成了$\mathbb{R}^{1 \times 1 \times C}$
激励(Excitation)
为了利用挤压之后的数据,我们需要使用激励去抓住通道与通道之间的依赖关系
激励操作需要有两个要求:
- 灵活,可以描述到非线性关系
- 它学习到的是不互斥关系(这里原文的描述有点意思:我们想要保证我们所强调的不是one-hot激活,我将其理解我一个表征可以被多个卷积核所学习到,而不是一个表征仅被一个卷积核所学习。否则卷积核之间也不存在什么大关系)
SE块使用了一个双层的神经网络去学习这个操作
$s=F_{ex}(z, W)=\sigma_2(g(z,W))=\sigma_2(W_2 \sigma_1(W_1z))$
其中$\sigma_1$和$\sigma_2$都是激活函数$W_1\in \mathbb{R}^{C\times {C\over r}}$,$W_2\in\mathbb{R}^{ {C\over r} \times C}$
公式中没有标识偏转bias,但是其实就是Full Connection
注意一下$W_1$和$W_2$的结构,为了减少计算复杂度并且帮助泛化,SE块使用了两层FC形成了一个瓶颈
$r$是减少比例
由于神经网络在低层比较一般,在高层比较特化,所以促进特征提取和类型特化的激励操作可以有益于表征的学习
综合
操作结束后,将u和s乘起来
$\widetilde{x_c}=F_{scale}(u_c, s_c)=s_c \cdotp u_c$
应用
作者将SE块和Inception和ResNet结合起来,形成了SE-Inception和SE-ResNet。其实也侧面反映出SE块的灵活性
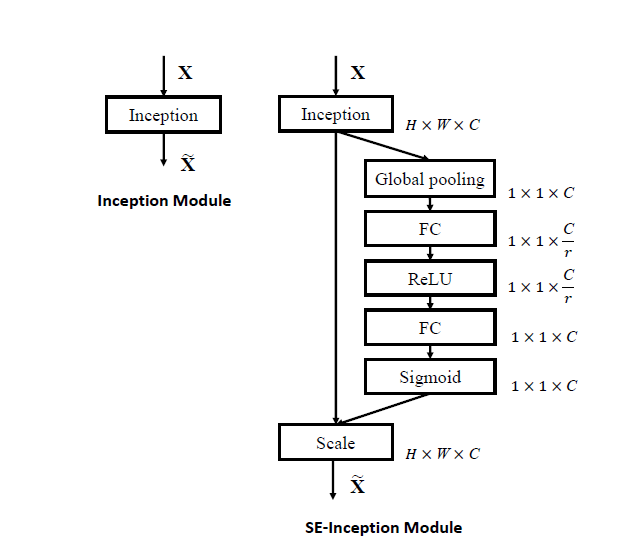
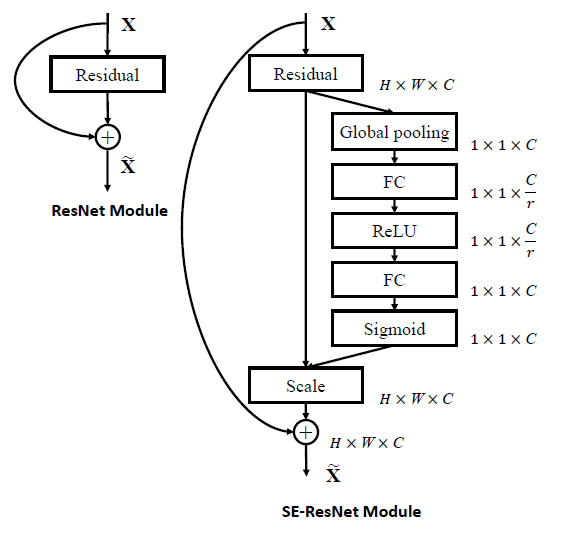
这里我有个想法:因为Residual是两个或多个卷积层堆起来的,按照作者的写法就是两个或多个卷积层一个SE块。如果一个卷积层一个SE块的performance会不会更好?可以做一下实验
值得一提的是,加过SE后的神经网络的performance都比没加过SE的要好
实际上SE并没有增加多少参数数量,但是却能够增加卷积层之间的连接与依赖的。从某种意义上来说,我没发现SE的明显的缺点
SE增加的参数数量为
${2 \over r}\sum^S_{s=1}N_s \cdotp {C_s}^2$
其中S是整个网络有多少层,$N_s$代表对于某一层SE重复了几次。
PS:
虽然是这么写的,但是我认为不完全是这么算
对于$N_s\neq1$的情况下,作者的意思是每一层会重复的Excitation
但我认为,这个情况下更好的选择应该是将一个Excitation设置成多层神经网络而不是二层
所以假设$N_s$代表Excitation中有$2N_s$的神经网络层数
那么参数数量为
$\sum^S_{s=1} {(N_s-2) \cdotp { {C_s}^2}\over r^2} + { {2{C_s}^2}\over r}$
但是我也不知道这样做的效果会怎么样。只能说有待实验
Appendix:减少比例r
r是减少比例,是一个非常重要的超参数
过小的r没有起到减少参数数量的目的
过大的r会使表现力下降